

生成AI(OpenAI)に対して独自データを利用する方法
- 関連データを学習させる、追加学習(ファインチューニング)というAIモデル自体の追加学習
- AIの質問時に補足情報を付けたして送信しAIが回答する、Groundingというナレッジサービスとの連携
方法 | モデルの運用 | 必要データ量 | 独自カスタマイズ性の回答制度 | 複雑な文章への対応 |
| 追加学習 | 元のモデルの新規バージョンに対応が難しい | 大量 | データ量とデータ精度 | 精度高い |
| Grounding | 元のモデルの新規バージョンに対応しやすい | 少量 | ナレッジの精度による | 精度低い |


- role (OpenAIと連携時のロール)
- system: AIアシスタントの設定等を記述、ChatGPTでは特に見えない箇所
- assistant: AIからの回答
- user: ユーザーからの質問
- tool: ナレッジデータ
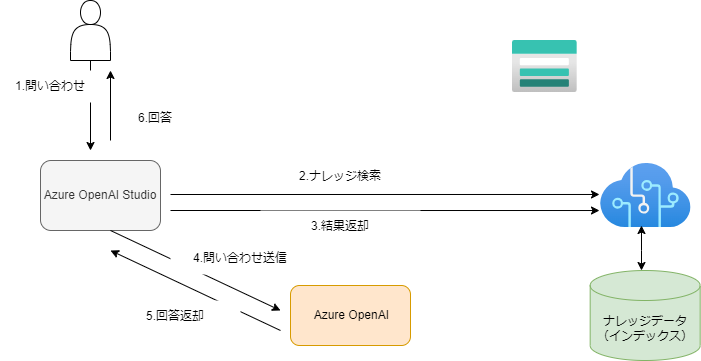
通常はuser情報だけを送信するのですが、Add your dataを利用する場合は toolにナレッジデータを付与してAI側に送信します。AI側はその情報を含めて回答します。そのため、ナレッジデータの精度によりAIからの回答制度はだいぶ変わります。OpenAIの仕様でトークン数という渡せるデータ量に限りがあるため、大きな文章量は処理できなくなります。送信時に2000語ぐらいを想定してください。
Azure Cognitive Searchとは
Cognitive Searchのデプロイ
データのインポート(インデックスへデータ格納)
データソースの設定
インデックスの作成
| データ格納方法 | データ格納形式(拡張子) | 言語対応 | 備考 |
| Azure OpenAI Studio | TEXT, Markdown, HTML, Microsoft Word, Microsoft Power Point, PDF | 英語のみ対応 | 大量データを運用しずらい |
| Azure Cognitive Search Indexer | CSV, EML, EPUB, GZ, HTML, JSON, KML, Microsoft Office形式,オープンドキュメント形式, PDF, TEXT(プレーンテキスト), RTF, XML, ZIP | 複数言語対応 (日本語対応) | 長い文章を含んだファイルはインデックスに格納されるが、OpenAIと連携不可 |
| データ取得スプリプト | TEXT, Markdown, HTML, PYTHON, PDF | 複数言語対応 (日本語言語対応) | PDFをインデックスデータに格納するためにはAzure Form Recognizerのデプロイが必要 OpenAIと連携できる文字数に分割 |
インデクサーの動作
Azure OpenAI Add your dataの利用
Azure OpenAI Add your dataの簡易検証を実施します。
データの設定
- ストレージアカウント作成済み
- Azure Cognitive Searchデプロイ済み
- Azure OpenAIモデルデプロイ済み
データの登録
Azure OpenAI Studioにアクセスします。
PlaygroundのChatを選択して下記画面を表示します。

画面真ん中のAdd your data(preview) を選択します。その後 Add a data sourceを選択します。
■ Data Sourceの設定
Select data sourceで Upload files を選択します。 ※ここで3種類の選択があります。既存のインデックスと連携するときは変更します。

Select Azure Blob storage resourceには、先に作成したストレージアカウントを選択します。CORSの許可が出る場合は許可します。
Select Azure Cognitive Search resourceには、先に作成したCognitive Searchを選択します。※Freeプランでは利用できません。
Enter the index nameには、作成するindexの名前を入力します。
※Add vector search to this search resourceでは検索精度を高める一つベクトルデータ形式にする方法ですが、今回は利用しないためチェックしません。
一番下のチェックリストCognitive Searchを利用するとお金がかかることにチェックを入れます。
最後にNextを選択します。
■ Upload filesの設定

ドラッグ&ドロップでファイルをアップロードします。その後、Upload filesを選択するとファイルがストレージアカウントに格納されます。StateがUploadedになりましたら、Nextを選択します。
アップロードするファイルとしてサンプルでは下記の記載になります。
maedalike.txt
前田周哉はSIOSのエンジニアです。みかんをこよなく愛しており、ミカンジュースを飲みすぎて病気になりました。
前田周哉の女性の好みは北斗晶です。■Data management
デフォルト設定のままNextを選択します。
Search TypeはKeywordを選択してNextを選択します。
※検索精度を上げるためにSemanticにする場合はCognitive Searchの設定を追加する必要があります。追加コストが必要です。

■ Review and finish
下記画面のように表示されます。Save and closeを選択します。

■元の画面に戻りインデックスのデータ登録


独自データの検証
独自データの検証を行います。
Limit responses to your data contentがチェックされた状態だと、登録したデータの内容をもとに回答します。
日本語データの検索性能は低く(英語認識のため)、さらにデータ数が少ないため、ConfigurationのParametersの設定でTemparture(創造的な回答度合い)を0.5に上げます。
その後上記データで、『前田周哉の好みは何ですか?』と入力するとが回答が返ってきます。

回答が返され、さらにreferences情報が表示されます。リファレンスを確認するとリファレンスの内容も表示されます。

このように独自データを利用して生成AIの回答をすることができます。
さいごに



{kind=link}