

生成AIの分野でもRAGは特に注目を集めており急成長している分野です。あまりに多くの情報に溢れており、各手法をどう捉えてよいか分かりにくい状況にあります。このブログではRAGがどのように成長し、どのような改善が試みられているのかを整理して、包括的で体系的に理解できるような説明を試みました。読んでいただいた方の理解の助けになれば幸いです。
RAGの概要
LLMは非常に優れた効果を発揮したものの、嘘を答えてしまうハルシネーションや古い知識での応答、回答の根拠の分からない不明瞭な推論といった問題を抱えています。RAGはこれらの課題に対し外部データベースを取り入れるというアプローチで解決を試みており、特に注目を集めている分野であり急速に進化しています。また、外部データベースを取り入れるという特性からドメイン固有の知識とLLMを組み合わせることができるため、企業からも大きな注目をされており研究・開発を実施されています。
基本的なRAGシステムのシナリオは図1のようになります。まず、ユーザがシステムに対して質問を投げかけます。システムは質問を元にデータベースに関連するドキュメントを問い合わせます。そのドキュメントを元にLLMが回答を生成しユーザに提供します。これによりユーザは従来の単純な検索システムよりもLLMを介することによって柔軟な質問でデータにアクセスしたり、的確な回答を得ることを期待できます。

(図1: 基本的なRAGの動作。Retrieval-Augmented Generation for Large Language Models: A Survey [1]より引用)
しかし、単純な方法では期待されたほどの効果は得られないことが分かってきており、現在は様々な改善が試みられているという状況です。その改善について説明していきます。
RAGの進化とパラダイム
RAGのパラダイムはNaive RAG、Advanced RAGを経て、Modular RAGへと進化しています。Naive RAGは最も基本的なRAGでシンプルですが多くの課題を抱えています。Advanced RAGはNaive RAGのフローをベースとして各処理の改善したものとなっています。さらに、Modular RAGでは、RAGで必要な各処理をモジュール化し、それらを組み替えることで新たなパターンを生み出して大きな性能の改善を試みています。
Naive RAG (Baseline RAG)
Naive RAG(Baseline RAGと呼ばれることもあります)は最も素朴なRAGのことです。インデクシングではPDFやWord、Markdownの文書データをプレーンテキストに直した後に固定のトークンの長さ(100, 256, 512など)でチャンクに分割。チャンクごとのベクトル表現を計算し、ベクトルデータベースに格納します。検索ではユーザの質問をベクトル表現に変換し、データベースから類似度の高いコンテンツを検索して、ドキュメントから回答を生成します。
このRAGは大きなの欠点を抱えていると指摘されています[1]。
- 検索の課題: 検索の再現性や精度が悪く、不揃いで無関係なチャンクがヒットし、重要な情報が欠落してしまうという。
- 回答生成の困難: RAGでも単にLLMを利用する場合と同様にハルシネーションを起こすことがあり、無関係であったり、有害であったり、バイアスのある情報を出力しうる。
- 検索結果の統合のハードル: 検索さらた複数の結果をうまく統合できずに適切な応答ができないことがある。多くの文書から関連性や重要性を判断し、統合して、一貫性のある回答を引き出すことは困難である。これらには一度の検索処理では不十分である。
1度でもRAGを構築されたことがある方なら頷ける内容ではないかと思います。RAGは基本的にこれらの課題を解決しようと進化を続けています。
Advanced RAG
Advanced RAGはNaive RAGの基本的な処理フローを踏襲しつつ、検索や回答生成など各処理の品質の向上に着目し、回答の精度の改善をしようとしています。

(図2: Naive RAGとAdvanced RAGとModular RAGの処理イメージ。Retrieval-Augmented Generation for Large Language Models: A Survey [1]より引用)
図2のAdvanced RAGのオレンジ部分がNaive RAGに対し追加されているテクニックです。Advanced RAGのテクニックはもう少し複雑であったり他のオプションを含むものなので、この図で完全に表されている訳ではありませんが、インデックス化、検索手法、回答生成のそれぞれに対して改善しているのがAdvance RAGです。これらの改善については改善手法のセクションで紹介します。
Modular RAG
単純にRAGの質問、検索、回答生成という線形なプロセスの工程をそれぞれ改善するだけでは限界がみえてきました。そこで、Modular RAGはNaive RAGやAdvanced RAGを基本としつつ、RAGの機能のモジュール化により適応性と再利用性を向上しようとしています。図2のようにModular RAGではRAGの各機能がモジュールとなり、それらを組み合わせた「パターン」をちょうどLEGOブロックのように組み上げていくという方法をとります。
より具体的にModular RAGの内容を見ていきます。Modular RAGは次の3層に分かれたアーキテクチャを持ちます。
- モジュールタイプ (Module Type)
- モジュール (Module)
- 演算子 (Operator)
モジュールタイプは最上位のレイヤーで、RAGのインデックス作成や検索、生成といった工程を表します。モジュールは中間のレイヤーで、各工程で実施する機能でチャンク化やクエリルーティングなどのより具体的な機能を表します。最後に演算子は最下位のレイヤーで、構造化インデックスやHyDEなど具体的な実装を表します。
このような3層の抽象化を用いることで自在な組み合わせを実現します。図3はモジュール、サブモジュール、演算子の具体例です。

(図3: Modular RAGのモジュールの一覧。Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks [2]より引用)
インデックス作成 (Indexing)、検索 (Retrieval)、検索事前処理 (Pre-Retrieval)、検索事後処理 (Post-Retrieval)、回答生成 (Generation)という従来のRAGの機能をモジュールしたもののほかに、オーケストレーション (Orchestration)が存在します。オーケストレーションはModule RAGの重要なモジュールタイプで、異なるモジュール間の調整役を担います。データやクエリに基づいて適切なモジュールを選択してフローを制御することで、より多くのデータやクエリに対して適応できるようになります。
Modular RAGはツールやフレームワークを利用することで実現することができます。Modular RAGを実現するツールやフレームワークをいくつかご紹介します。
- CognitaはLangchain/LlamaIndexのラッパーのように動作し、RAGで必要なモジュールを提供し、Langchain/LlamaIndexを単体で用いるよりも再利用性が高まります。
- Advanced RAGが構築可能なHaystackと軽量なAI/機械学習の構成管理フレームワークであるHypsterを組み合わせることで実装することもできます[3]。
- AutoRAGはモジュールの組み合わせを自動的に選択できるという特徴を持つツールです[4]。G-EvalやRAGAsといった評価ツールを用いて、自動評価を実施し適切なパターンを走査してくれます。
まだ、この領域は発展途上であり成熟したツールは存在していませんが、注目度が高く変化が激しい状況です。今後さらに発展する領域と考えられ注視していく必要があります。
RAGの進化の過程
ここまでみたようにRAGはNaive RAG、Advanced RAG、Modular RAGという変遷を辿っています。これらのパラダイムは全く別ものではなく、前のパラダイムを拡張・改善する形で進んできています。Advanced RAGはNaive RAGの各処理をより洗練させ、Modular RAGはAdvanced RAGの処理をモジュール化し、その組み合わせのパターンによるより柔軟なアーキテクチャで非常に大きな工夫の余地を与えてくれています。また、最新のModular RAGというパラダイムが出たので、Advanced RAGは終わったかというとそういう訳ではなく、Advanced RAGにおける改善手法は現在でも進化を続けており、それがModular RAGのモジュールとなり進化していくという流れは続いています。そういう意味で今後しばらくの間は特定のパラダイムだけでなく全体を追っていく必要があります。
RAGとファインチューニング
RAGとファインチューニング(追加学習)は類似した技術であるためしばしば比較されます。ここではRAGとファインチューニングの関連について説明します。
RAGとファインチューニングの違い
RAGとファインチューニングはどちらもモデルがもともと持っていない情報をモデルに取り扱わせるという意味で同じですが、両者の方法はそれぞれことなります。RAGは前述の通りで外部のデータベースから情報を参照し、その情報を元に回答を生成します。通常、RAGでは事前学習されたモデルをそのまま使います。一方で、ファインチューニングはモデル自体にさらに追加の学習を行わせるという方法で、モデル自体(LLMのニューラルネットワークのパラメータ自体)が更新されて新しい情報を取り込みます。ファインチューニングは質問とそれに対する回答のセットである「学習データ」を用いてモデルを調整します。OpenAIなどのプラットフォームではこのような学習データをアップロードするだけで、ファインチューニングできる仕組みが提供されています[5]。
ファインチューニングは特定用途のタスクに対して効果的な能力を発揮します。例えば、特定ドメインの思考方法やより厳格な推論能力を向上などに効果が発揮されています[7]。しかし、多くの学習を行うと以前に学習したことを忘れてしまうといった「破壊的忘却」をしたり、学習した情報を回答できるようになってもその根拠を示せなかったり、新しいデータが更新されるたびにファインチューニングの手間がかかるといった課題があります。
RAGはファインチューニングがブラックボックス化してしまうのに対し、インデックス作成や検索・回答生成などの段階が見える形で存在しているためカスタマイズしやすかったり、データベースを更新すること情報が更新できるので最新を保ちやすいという特徴があります。しかし、RAGの回答は検索の品質に大きく依存しているため、RAGの構築は検索の工夫がどれだけできるかにかかっているとも言えます。
RAGとファインチューニングの性能
Microsoft Researchによる論文ではファインチューニングに対して、RAGの方が性能が高いと報告されています[6]。

(図4: Oren Elisha, Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs [6]より引用。)
この検証ではRAG単体が最も性能が良く、次にRAGとファインチューニングの組み合わせ、最後にファインチューニングという順で性能が高いという結果になりました。Llama2に関してはファインチューニングとRAGの組み合わせが最も高い結果となりました。したがって、検索という観点ではRAGが優れているでしょう。
RAGとファインチューニングの融合
検索ではRAGが優れていたからといってRAGだけを用いるだけでなく、RAGとファインチューニングは両方を活かすことができます。
前セクションの論文では知識を正しく取り出せるかに着目しており、それ以外のタスクに関する検証は行なっていないので、単純にファインチューニングがRAGより一般的に劣っていると判断する材料にはなりません。例えば、専門分野における推論能力の向上では専門分野のコーパスを用いてファインチューニングさせることで性能が向上されたことが報告されています[7]。このようなタスクに関しては原理的にRAGで対応することは難しいでしょう。
つまり、図5のように外部知識が必要となるタスク(External Knowledge Required)ではRAGが有効で、モデル適応が必要となるタスク(Model Adaptation Required)ではファインチューニングがより有効です。Moduler RAGではファインチューニングされたモデルを組み合わされる方法が使われてきています。

(図5: Retrieval-Augmented Generation for Large Language Models: A Survey [1]より引用)
改善手法
RAGで提案されている改善を次の3つに分けて紹介していきます。
- インデックス
- 検索
- 回答生成
インデックス
チャンク化戦略
チャンク手法はRAGに取り込む大きな文書の塊を小さく分割する手法です。分割されたチャンクごとにインデックスが作成されるため、チャンクは検索の品質に大きな影響を与えます。ここの内容は「Chunking Strategies for LLM Applications」[8]の内容を参考に説明します。
固定サイズチャンク
最も単純でNaive RAGで用いる方法が固定のチャンクサイズで機械的に分割する手法です。固定サイズのチャンクではチャンクサイズにはトークン数が用いられます。トークンとはTokenizerによって分割される単位です。通常は単語数や文字数ではないです。どのようにトークン分割されるかはTokenizer – OpenAI Platformなどを使って試すことができます。また、単純に固定のチャンクサイズで切ってしまうと文章の前後の繋がりの情報が失われてしまうため、隣り合ったチャンクで同じトークンを重複してもつ「オーバーラップ」を設ける必要があります。
この方法は自然言語処理(NLP)を必要としないため、計算量が小さいというメリットがありますが、全く文章の意味が考慮されないため、チャンクの質は悪くなりがちというデメリットがあります。
コンテンツ認識チャンク
固定サイズのチャンクは機械的で意味が考慮されないという点で、チャンクの質が悪いという問題点がありました。それに対し、コンテンツをきちんと認識した上で、より有効なチャンク化しようという方法もあります。その方法をいくつか紹介していきます。
(表1: 5つのコンテンツ認識チャンク。下の行ほど高度に意味を認識して分割するチャンク化方式。)
| チャンク方法 | 説明 |
| 文の分割 (Sentence splitting) | 区切り文字などを利用して文に分割してチャンクとして扱う非常に簡単な方法です。実装は単に「。」などの句点で分けるコードを自作する方法 (Naive splitting) があります。だた、そのような方法では例外的なパターンなどでは分離できないので、NLTKやspaCyなどのPythonのライブラリによって文を分割という方法も用いられます。ライブラリを用いることでより適切に文を分離することができます。 |
| 再帰的チャンク化 (Recursive Chunking) | 大きな文章をいくつかの文書に分割し、さらにその文書を分割するという処理を繰り返し、階層的かつ反復的に小さいチャンクに分割する方法です。再帰は指定されたチャンクサイズになるまで繰り返されます。分割には複数の区切り文字を使用します。再帰が繰り返される中で使用される区切り文字が変わり、目的のチャンクサイズになるように処理されます。実装はLangChainのRecursiveCharacterTextSplitterを用いる方法があります。 |
| ドキュメント固有のチャンク化 (Specialized chunking) | MarkdownやLaTexなどといった文書は構造化されていて、見出し、リスト、コードブロックなどの情報を用いることで、より正確にコンテキストを理解したチャンクを得ることができます。実装はLangChainのMarkdownTextSplitterやLatexTextSplitterを用いる方法があります。その他のドキュメントでも形式が明確なものであれば正規表現等を用いて、Splitterを自作することも可能でしょう。 |
| 意味的チャンク化 (Semantic Chunking) | Greg Kamradtによって導入された手法です。その名の通りで文章の意味によってチャンクに分解します。文章を文に分割し、文の意味が近いものを同じトピック、遠いものがあれば別トピックに切り替わったと判断して、チャンクに分解します。上記の文章の表面的な形式で分割していたのに対し、より踏み込んだチャンク化です。実装はLangChainのSemanticChunkerを用いる方法があります。 |
| エージェントによるチャンク化 (Agentic Splitting) | さらに先進的な手法として実験的ではありますが、AIエージェントによる分割も提案されています[10]。 |
ベクトル化
分割されたチャンクは埋め込みモデル (Embedding Model) によってベクトル化されます。モデルの選定やチューニングについてご紹介します。
埋め込みモデルの選定
ベクトル化では意味の近いベクトルは類似度が近く、意味が遠いものは類似度が遠くなる分類性能の高いベクトル化されることが望ましいです。そのため、埋め込みモデルの選定はインデックスの品質に影響します。多くの場合では、OpenAI社のada v2などのモデルを利用することが多いですが、モデルの選択はリーダーボードを確認し、指標を比較して独自にモデルを選ぶことができます。リーダーボードでは多くのモデルに対しベンチマークを実施してその結果が公開されています。例えば、有名なリーダーボードとしてはMTEB LeaderboardやNejumi Leaderboardなどがあります。特にNejumi Leaderboardは日本語での性能を評価したもので、日本語を扱う際のモデル選定では参考になります。
埋め込みモデルのファインチューニング
医療や法律など専門用語などは一般的な語用とは異なる場合があり、意図したベクトル化がされないことがあります。そのような場合には埋め込みモデルのファインチューニングが有効なケースがあります。LLamaIndexなどではファインチューニングが可能です。
構造インデックス
インデックスの構造によっても検索の精度が変わります。ここではいくつかのインデックスの方法について「Advanced rag techniques: an illustrated overview」[9]を中心にご紹介します。
ベクトルストアインデックス (Vector store index)
最も単純に質問と回答のベクトルの類似度の近いものを検索する方法です。Naive RAGで使われる最初のアイデアです。ベクトル類似度と近傍探索のアルゴリズムは複数あります。
まず、ベクトルの類似度の計算についてElasticSearchでよく次の演算が使われています[11]。これらはElasticSearch固有の概念ではなく、数学や物理、情報工学で広く使われています。
- マンハッタン距離 (L1距離)
- ユークリッド距離 (L2距離)
- コサイン類似度
- ドット積 (内積、点乗積)
意味ベクトルは方向によって意味が表される性質があるので、RAGの文脈ではコサイン類似度やドット積といった「点」ではなく「ベクトル」として扱われる演算が相性がよく比較的精度がよいといえます。また、コサイン類似度はベクトルの角度のみが考慮されますが、ドット積はベクトルの長さも考慮されるのでより多くの情報を持ちます。しかし、情報が多ければよいというわけでもなく、長さがノイズになる場合もあるため比較して検討が必要となります。
次に近傍探索についてみていきます。近傍探索とは周辺にあるベクトルを探すためのアルゴリズムです。その方法には主に次の2つが存在します。
- k最近傍法 (k-Nearest Neighbor: kNN)
- 近似最近傍法 (Approximate Nearest Neighbor: ANN)
kNNはすべてのデータを比較して近いベクトルを見つけ出すアルゴリズムで、正確にベクトルを見つけ出すことができます。しかし、単純に全てのベクトル同士の距離を比較してしまうと、すべてのデータを探索することになり検索に非常に大きな時間がかかってしまうことになります。ちょうどリレーショナルデータベースでインデックスのないカラムに線形検索するようなものです。そのため、データベースとしては小規模〜中規模程度のデータベース向けで、大規模の場合にはRAGの応答性を犠牲にしても正確性を求める場合に利用します。
ANNは多少正確さを犠牲にして素早く近傍のベクトルを見つけるためのアルゴリズム全体の総称です。現在はその主流のアルゴリズムとしてHierarchical Navigable Small World (HNSW)が使われています。HNSWのアルゴリズムを簡単に説明します。図6のようにベクトルの近さをグラフとして表現し、グラフの詳細度で複数のグラフを構築します。この際に各グラフに対応するノードを設けます。このグラフを粗い方からたどり、クエリのベクトルに近いノードを探します。次にそのノードに対応する1段詳細度の高いグラフに移動し、もう一度探索します。最後は実際のベクトルと対応したグラフに移動し、最も近い(可能性が高い)ノードを発見します。イメージ的には札幌・仙台・東京・名古屋・大阪・福岡くらいしか書いていない広域の地図から場所を探して、次に関東周辺の地図から神奈川あたりが近そうだと分かり、神奈川県の地図から横浜みなとみらいを探し当てる感じといったところかと思います。
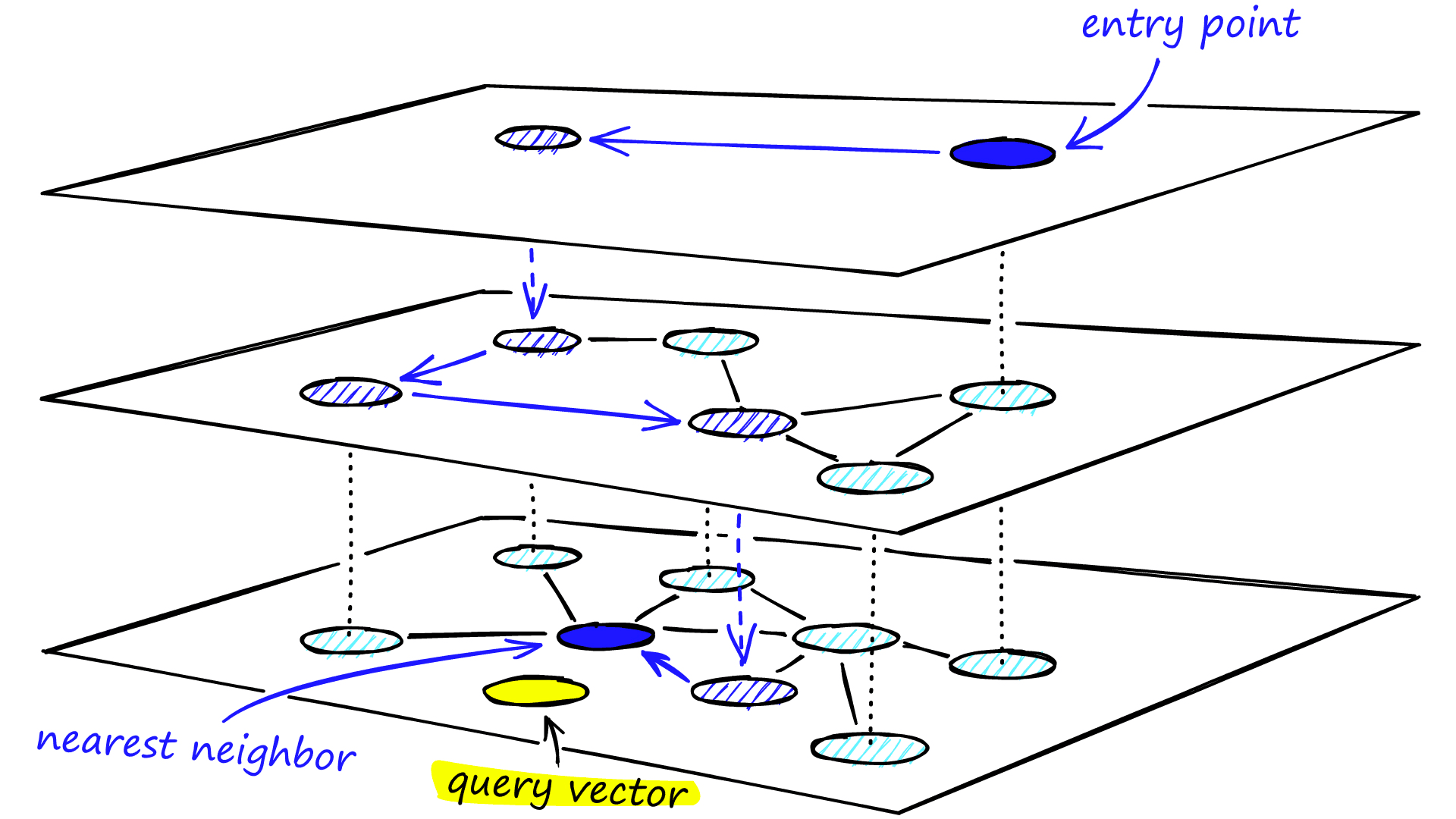
(図6: Hierarchical Navigable Small Worlds (HNSW) [12]より引用)
HNSWでもかなり正確な結果が得られることが一般に知られています。そのため、アルゴリズム選択にあたってはANN近傍探索はまずANNから検討を始め、どうしてもそれでは検索精度が悪い場合にはkNNを選択するという進め方がよいでしょう。
多くのデータベースでは計算方法や近傍探索アルゴリズムを変更できるパラメータが用意されています。サポートされている計算方法・近傍探索はデータベースにより異なりますので、ドキュメントをご確認ください。
チャンクのメタデータ
チャンクにページ番号やファイル名、カテゴリ、タイムスタンプなどのメタデータを付与する方法があります。チャンク生成時にデータベースにこれらのメタ情報を一緒に保存するように実装します。このメタデータで検索範囲の絞り込みをしたり、タイムスタンプでの絞り込みで古い情報を排除するなどして検索の精度を高めることができます[1]。
階層的インデックス (Hierarchical indices)

(図7: Advanced rag techniques: an illustrated overview [9]より引用)
大規模なドキュメントを検索する際に細切れの小さなチャンクでは適切にコンテキストを保持できないという欠点がありました。そこで階層的インデックスのアプローチでは図7のように要約のチャンクに対して検索を実施し、さらに要約に関連づけられたより小さなチャンクを検索するという方法をとります。階層は要約の単位を変えることで複数に増やすことができます。これにより関連性の高いドキュメントを発見したり、要約の階層のドキュメントを回答に使うことができるなどのメリットがあります[13]。
実装についてはNirDiamant氏により参考となるHierarchical Indices in Document Retrievalが公開されています。
想定質問(Hypothetical Questions)
Naive RAGではユーザからのクエリをベクトル化することで検索を行いますが、質問のベクトルから内容のベクトルを検索するという動きになり、それらは必ずしもベクトルが類似するとは限りません。そこで、質問のベクトルから質問を検索したり、回答のベクトルから回答を検索するといった方法が提案されました。
想定質問(またはReverse HyDE)は質問のベクトルから質問を検索する方法で、インデックスの作成時点で内容に対する想定質問をLLMに生成させ、その質問をベクトル化したものをデータベースに格納します。例えば、「富士山の標高は3,776mです」というチャンクに対して、その文章そのもののベクトルでなく、LLMで質問「富士山の標高は?」という想定質問を生成します。この文章に対するベクトルをベクトルストアに保管します。するとユーザが質問した「富士山の高さはどのくらい?」との類似度が高くなる可能性が高く精度が高くなると予想できます。
Reverse HyDEと呼ばれている理由はHyDE(後述)が質問に対する「想定回答」で検索するというアプローチをとっており、その逆のアプローチであることからそのように呼ばれています。
周辺コンテキスト拡充 (Context enrichment)
インデックス作成時にチャンクに周辺の文章を付与してLLMに推論させる方法です。LLMは検索したチャンクだけでなく周辺の文章を用いることができるので、文脈をよりよく理解して回答を生成することが期待できます。センテンスウィンドウ検索と自動マージ検索の2つの方法があります。
センテンスウィンドウ検索 (Sentence Window Retrieval)は単純に検索されたチャンクの周辺の文章をLLMに送る方法です。下図の緑の部分が検索で引っかかったチャンクであり、拡大して黒の文章を付与します。

(図8: Advanced rag techniques: an illustrated overview [9]より引用)
自動マージ検索 (Auto-merging Retriever (別名 Parent Document Retriever))はチャンクを親と子に分けて検索する方法です。まずは通常通り小さいチャンク(これを「子チャンク」という)に対して検索を行い、ヒットした子チャンクの属する親のチャンクを取得し、より大きな親チャンクの方をLLMに送る手法です。

(図9: 自動マージ検索のイメージ。Advanced rag techniques: an illustrated overview [9]より引用)
具体的な実装については例えばLlamaIndexを使った方法でRecursive Retriever + Node Referencesを参照ください。
ナレッジグラフ (Knowledge Graph)
これまでのところはクエリに対していかに近い文章を取得したり、いかに周辺の文章も含んでコンテキストを保持するかがメインのテクニックでした。しかし、これだけでは不十分でクエリとは直接関連しなくとも、検索された文書とは関連して回答したい内容については取得できず、十分な回答が生成されなかったり、ハルシネーションを起こすという欠点がありました。
ナレッジグラフはそのような欠点を解決するために知識と知識を関連付けたグラフ型のデータベースを構築し、ベクトルストアデータベースよりも関連した情報を包括的に検索できるように考えられています。
ナレッジグラフの動作について簡単に説明します。ナレッジグラフとは図10のようなノード(丸)とエッジ(線)からなっており、ノードで対象となるオブジェクトを表し、エッジでそれらの関係性を表すグラフとなっています。RAGではノードに対してチャンクを割り当て、チャンク間の関連をエッジで表します。これによりベクトルストアインデックスで表現できなかった関連性を表現することができます。

(図10: LangChainのLLMGraphTransformerで構築したナレッジグラフをNeo4jで表示した例。Enhancing RAG-based application accuracy by constructing and leveraging knowledge graphs [14]より引用)
検索は多くの場合ベクトルストアインデックスと併用で実装されるケースが多いです。手順としてはまず質問に対してベクトルストアからチャンクを取得し、そのチャンクに関連する情報をナレッジグラフから検索するという方法です。

(図11: ベクトルストアインデックスとナレッジグラフの併用。Enhancing RAG-based application accuracy by constructing and leveraging knowledge graphs [14]より引用)
実装についてはLangChainのLLMGraphTransformerを用いる他に、現在注目されているのが、Microsoft Researchにより提案されているGraphRAGです。Graph RAGは2段階のナレッジグラフを用いて、部分的な知識の要約を1段階目で生成し、2段階目でその要約全体を用いて質問するため、従来手法より回答精度が高いとされています[15]。
検索
複合検索とハイブリット検索 (Fusion retrieval or hybrid search)
複数の検索手法を用いることで検索精度を向上させようとする方法は多く用いられています。基本的にはベクトル検索がベースとしてもちいられ、ベクトル検索の弱点を補う形で用いられることが多いです。特に代表的なものをご紹介します。
キーワード検索
ハイブリッド検索では多くの場合、ベクトル検索とキーワード検索の両方を用いることをいいます。キーワード検索とは単語や語句から文書を検索することを言います。RAGでは質問に含まれる単語や語句を自然言語処理によって抜き出してきて、一致したキーワードを含む文書を見つけ出します。
これはベクトル検索が意味として近い文章を見つけ出すのが得意なものの、同じキーワードが含まれていたとしてもベクトルの類似度が低ければ検索にヒットしないという弱点を克服するために用いられる方法です。
セマンティック検索
セマンティック検索は語句や単語の「意味」を基に検索をする検索方法です。例えば、「携帯」という単語から「ケータイ」「電話」や「iPhone」など似た意味の単語もヒットします。
これもキーワード検索との併用の効果と同じく、類似度が低くても近い意味合いの単語が使われているチャンクを取得することができます。
タグ検索
前述のチャンクのメタデータで紹介した通り、あらかじめチャンクにメタデータを付与しておくことで、データを絞り込み検索精度を向上することができます。
グラフ検索
前述のナレッジグラフで紹介したとおり、ナレッジグラフを用いることで関連する文書より包括的に取得できるようになり、検索精度を向上することができます。
クエリ
ユーザから提示された質問は必ずしも検索に対して最適とは限らず、クエリに対し何らかの工夫を施した方が検索精度が上がるといわれています。
クエリ拡張
単一のクエリだけを用いるのではなく、複数のクエリを使ったり、1つのクエリをより簡単なクエリに分割する検索の精度を上げる手法です。クエリ拡張には次の種類があります。
- マルチクエリ (Multi-Query)
- サブクエリ (Sub-Query)
マルチクエリ (Multi-Query)はユーザからのクエリを別の観点を取り入れて複数のクエリを生成する手法です。これにより単一のクエリだけでは取得できなかった結果を取得することができます。ユーザからのクエリの微妙なニュアンスの違いでベクトル検索にヒットしないような内容も取得できるといった効果が期待できます。実装ではMultiQueryRetrieverを使う方法があります。実際にMultiQueryRetrieverを使ってクエリを生成すると次のようになります。
元のクエリ: What are the approaches to Task Decomposition? (和訳: タスク分解へのアプローチは何ですか?)
質問1: How can Task Decomposition be achieved through different methods? (和訳: さまざまな方法でタスク分解を実現するにはどうすればよいでしょうか?)
質問2: What strategies are commonly used for Task Decomposition? (翻訳: タスク分解に一般的に使用される戦略は何ですか?)
質問3: What are the various ways to break down tasks in Task Decomposition? (和訳: タスク分解でタスクを細分化するさまざまな方法は何ですか?)
(MultiQueryRetrieverより引用・改変)
このようにさまざまな聞き方の質問に変換されていることがわかります。これにより多くの情報を得られる可能性が高まります。
サブクエリ (Sub-Query)はユーザからのクエリを複数のクエリにより簡単なクエリに分割して検索する手法です。ユーザからの質問は複数の質問が関連したものであることがあり、そのようなケースでは一度のクエリでは解決できず、単純な質問に分割して検索することで的確な情報を取得できる効果が期待できます。実装はプロンプトエンジニアリングを使用して、質問を分割するようにLLMに指示します。実装例はPart 7: Decomposition – Rag From Scratch: Query Transformationsに示されていますので参考としてください。実際にクエリを生成すると次のようになります。
元のクエリ: how to use multi-modal models in a chain and turn chain into a rest api (和訳: チェーン内でマルチモーダル モデルを使用し、チェーンを REST API に変換する方法)
質問1: How to use multi-modal models in a chain? (和訳: チェーン内でマルチモーダル モデルを使用するにはどうすればよいでしょうか?)
質問2: How to turn a chain into a REST API? (和訳: チェーンを REST API に変換するにはどうすればいいですか?)
(Decompositionより引用・改変)
このように複数のトピックが含まれているような質問が分割されていることがわかります。
クエリ変換
クエリ変換は元のクエリを変換することで、検索の精度を上げる手法です。よくある方法としては次があります。
- HyDE
- Step Back
HyDEは回答のベクトルから回答を検索する方法で、質問に対する回答を検索なしでLLMに作成させ、その質問をベクトル化したものでデータベースから検索します。検索なしで回答させるという点について不思議に思われるかもしれませんが、これは検索しなくともニュアンスの似た回答が得られるはずだという仮説に基づきます。例えば、元のクエリが「日本で一番高い山は何ですか?」であった場合に検索を用いずにLLMから「日本で一番高い山は高尾山です」という仮の回答を得ます。これは当然ハルシネーションですが、チャンクに「日本で一番高い山は富士山です。」という文章が含まれていれば、仮の回答とチャンクのベクトルは近いはずです。実際にBM25やContrieverと比較して精度が高いことが報告されています[16]。実装についてはPart 9: HyDE – Rag From Scratch: Query Transformationsに示されていますので参考としてください。
Step Backは元のクエリをより抽象的な質問にLLMで変換させ、元のクエリと抽象的な質問の両方を使って検索を実施する手法です。これにより主に複数の情報源から結果を導き出すマルチホップ推論が必要な場面での精度が向上されたと報告されています[17]。実装についてはPart 8: Step Back – Rag From Scratch: Query Transformationsに示されていますので参考としてください。
ルーティング
検索は1回だけではなく、複数回実施するのも有効な手段です。

(図12: 反復検索と再帰検索と適応検索のフローチャート。Retrieval-Augmented Generation for Large Language Models: A Survey [1]より引用。)
単一検索
Naive RAGで使われる単純な検索方法で、一度の検索で得られた結果を用いて回答を生成する方法です。シンプルな手法で応答性も高いものの、一度の検索では適切な回答を得られないことが多いという課題があります。
反復検索
反復検索は以前の検索結果を用いて、関連する文書を繰り返し取得する方法です。これにより周辺のコンテキストを補うことが期待できます。ただし、ノイズとなる情報が増えてしまうこともあります。
再帰検索
再帰検索は以前の検索結果を用いて、Chain-of-Thought (CoT) を用いてクエリを改善し、繰り返し検索をする方法です。この方法では検索結果のフィードバックを受けて、徐々に関連性の高い文書を探し当てることができます。
適応検索(AIエージェント)
適応検索とはLLMが次の検索をどのようにするかの次のアクション自体を考えさせるという方法です。最近特に注目を集めているのは適応検索の領域です。Flare、Self-RAG、AutoRAG、Toolformer、Graph-Toolformerなどのツールが提案されていますが、ここではより注目度の高いAIエージェントを用いたマルチドキュメントエージェント型の手法について簡単に説明します。

(図13: マルチエージェント型のアーキテクチャ例。Advanced rag techniques: an illustrated overview [9]より引用)
図13のようにエージェントは担当するインデックスごとのドキュメントエージェントが配置され、ドキュメントエージェントを総括するトップエージェントの構造からなります。ドキュメントエージェントはトップエージェントに指示に合わせて、ベクトルストアインデックスと要約のインデックスなどデータベースへの問い合わせを自立して判断し実施します。トップエージェントはクエリをどのように分割して、各ドキュメントエージェントに引き渡したり、回答を統合したりについて判断します。これにより異なるドキュメントからの情報を統合した高度で洗練された回答得ることが可能になります。しかし、この手法はエージェント間の多段で複雑なクエリと回答の段階を踏むため、応答に時間がかかるというデメリットもあります。実装はLlamaIndexのMulti-Document Agentsを用いることができます。
回答生成
再順位付けとフィルタリング
検索では必ずしも関連性の高い文書だけがヒットするわけではなく、関連性が薄くノイズとなるものも混在します。検索で得られた結果を改めて関連性の高い順番に並べ替えたり、フィルタリングするという方法がよくとられます。LlamaIndexの調査では再順位付けを実施することで精度が高くなるといわれています[18]。
LLMのファインチューニング
RAGとファインチューニングの有効で述べた通り、単純な知識の検索ではRAGが優れるものの、RAGとファインチューニングは両方を用いることができます。GPT-3.5-Turboをファインチューニングし、RAGAsでの評価を行った結果、回答の関連性や忠実性が向上したと報告されています[19]。
レスポンスシンセサイザー
最終的な応答生成は複数のチャンクを用いて回答を生成することになります。要約だけを示すような回答に調整したり、詳細まで説明を加えたり、精度を少々犠牲にしてLLMのトークン消費を節約するなどのケースが考えられます。LlamaIndexではResponse Synthesizerという機能を提供しており、その中で回答生成方法のオプションをいくつか用意されています。
まとめ
- RAGのパラダイムはNaive RAG、Advanced RAG、Modular RAGに進化している。
- Advanced RAGではインデックス化、検索、回答生成のそれぞれに改善が提案されている。
- Modular RAGでは多くの手法をモジュール化し、組み合わせパターンを柔軟に作り出す。
最後までお読みいただきありがとうございます。お気付きの点などありましたら、ぜひコメントください。
【宣伝】生成AI ネクストテックソリューションのご紹介
弊社サイオステクノロジーでは生成AIを用いたトレーニング、コンサルティング、アプリケーション開発のソリューションを提供しています。ご興味のある方はぜひお問い合わせください!

https://nextech-solutions.sios.jp/genai/
参考文献
- Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, Haofen Wang, Retrieval-Augmented Generation for Large Language Models: A Survey, 2024.
- Yunfan Gao, Yun Xiong, Meng Wang, Haofen Wang, Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks, 2024.
- Gilad Rubin, Implementing “Modular RAG” with Haystack and Hypster, 2024.
- Dongkyu Kim, Byoungwook Kim, Donggeon Han, Matouš Eibich, AutoRAG: Automated Framework for optimization of Retrieval Augmented Generation Pipeline, 2024.
- OpenAI, Fine-tuning Fine-tune models for better results and efficiency.
- Oded Ovadia, Menachem Brief, Moshik Mishaeli, Oren Elisha, Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs, 2024.
- 森下皓文, 山口 篤季, 森尾 学 , 今一 修 , 十河 泰弘, 日立製作所 研究開発グループ, シェフィールド大学, 帰納的に多様な巨大論理推論コーパスによりLLMの汎用論理推論能力を向上させる, 2024.
- Roie Schwaber-Cohen, Chunking Strategies for LLM Applications, 2023.
- IVAN ILIN, Advanced rag techniques: an illustrated overview, 2023.
- Greg Kamradt, 5 Levels Of Text Splitting, 2024.
- Valentin Crettaz, Vector similarity techniques and scoring, 2024.
- Pinecone, Hierarchical Navigable Small Worlds (HNSW).
- Nirdiamant, Hierarchical Indices: Enhancing RAG Systems, 2024.
- LangChain, Enhancing RAG-based application accuracy by constructing and leveraging knowledge graphs, 2024.
- Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Jonathan Larson, From Local to Global: A Graph RAG Approach to Query-Focused Summarization, 2024.
- Luyu Gao, Xueguang Ma, Jimmy Lin, Jamie Callan, Precise Zero-Shot Dense Retrieval without Relevance Labels, 2022.
- Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H. Chi, Quoc V Le, Denny Zhou, Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models, 2024.
- Ravi Theja, Part 7: Decomposition – Rag From Scratch: Query Transformations, 2023.
- LlamaIndex, Fine Tuning GPT-3.5-Turbo.


