

はじめに
こんにちは、サイオステクノロジーの小沼 俊治です。
今回は、AIを活用した RAG(Retrieval-Augmented Generation: 検索拡張生成)アプリケーションの仕組みを無料で体験でき、コンテナで簡単に構築できるハンズオン環境を用意しました。
このハンズオンでは、LangChain、LLM に PC 内のローカルで動かす Open source LLM、ベクトルデータベースの Milvus といったオープンソースのプロダクトを使用します。
学習は、JupyterLab(Jupyter Notebook) の Notebook 形式でステップごとに用意した教材を使って進めます。
教材はステップ1から5までで構成しており、ステップ1から4では、外部に存在するデータの収集からデータを活用した回答生成まで、RAG を構成するモジュールを作成しながら一連の流れを学習します。集大成となるステップ5では、これまでに作成したモジュールを組み合わせて Web アプリケーションを構築し、アプリケーションの利用を通じて RAG を体験します。
LLM はローカルで動かすので、少々(PC の)スペックは必要ですが、トークン数などのコストを気にする必要はありませんので、思い存分、体験と学習に挑んで頂けると思っています。

構成概要
ハンズオン環境の構成
筆者が動かした際の主な構成要素は以下の通りです。
- Windows 11 Professional
- WSL 2.5.9.0
- Ubuntu 24.04.3 LTS
- Docker Engine 28.5.1

ハンズオンを構成する環境は以下の通りです。
- 教材を活用しながら学習を進める環境として、JupyterLab で LangChain を使う Python 環境を Ubuntu に構築します。
- RAG の処理で必要となる Embedding や Open source LLM などのモデルは、Huggin Face からダウンロードして取得します。
- 拡張検索に必要となるデータを蓄積するベクトルデータベースには、Milvus を「milvus-standalone」、「milvus-etcd」、「milvus-minio」コンテナで構築します。
- Milvus をビジュアル的に管理できる Web UI 管理ツールの Attu も「milvus-attu」コンテナで構築します。
環境構築や各種設定に使用するそれぞれのファイルは、以下の GitHub リポジトリで公開しています。
$ tree ~/handson/hands-on-rag-with-langchain/
hands-on-keycloak/
|-- container/ …… 「環境構築」章でコンテナ作成で使う素材
| |-- docker-compose-attu.yml
| :
|
|-- setup/ …… 「環境構築」章でツール準備の環境準備に必要な素材
| |-- SETUP_HANDS-ON.sh
| :
|
`-- try-my-hand/ …… 「ハンズオン実施」章で教材を進める環境
|-- cmd01-before_python_virtual_env.sh
|-- cmd02-start_jupyterlab.sh
|
|-- data/ …… ハンズオンでベクトル化する元データの素材
| `-- recurrent_navi_tyo.xlsx
|
|-- lesson/ …… ハンズオンで利用するステップごとの教材
: :RAG の仕組み
教材でハンズオンを始める前に、教材を構成する各ステップの元となる RAG の仕組みを理解します。
仕組みを表したイラスト

仕組みの流れを説明
図中の1から2はベクトルデータベースに類似検索に利用するデータの蓄積フェーズを意味し、
図中の3から9はベクトルデータベースに蓄積されたデータを類似検索で活用する応用フェーズを意味します。
- 日々の経済活動を通じて、以下をはじめとするデータが企業のシステムに溜まります
- 販売する商品の在庫管理情報や売上データ
- 経済取引を記録する会計データ
- 企業に関わる人材を把握する社員情報や顧客情報
- 企画提案、商品説明、および企業説明等で作成されたドキュメントファイル
など
- 企業に溜まったデータを検索に活用するために、以下をはじめとする加工を施しながらベクトル化して蓄積します
- 検索効率が向上するサイズにデータを細切れに分割するチャンキング
- ベクトルデータベースで類似検索が出来るように数値ベクトルに変換するエンベディング
- 必要に応じて検索効率を向上させるため欠損値の削除や補完、値形式を揃えるクレンジング
- 日々の業務活動を進めるに当たり不明点があれば質問を投げかけます
- 投げかけられた質問をエンベディングしてベクトルデータベースに対して類似検索します
- 投げかけられた質問に関連するデータを類似検索結果として戻します
- LLMに回答を生成を依頼するために、依頼向けテンプレートに質問と類似検索結果を付与してプロンプトを作成します
- 質問に回答するためにプロンプトを用いてLLMに回答案の作成を依頼します
- LLMが生成された回答案を戻します
- LLMから戻された回答案を整形して質問者に回答を戻します
事前準備
Hugging Face のアカウント準備
Hugging Face より Embedding Model や Open source LLM を取得して利用します。取得には事前に、アカウント登録、Access Token 発行、および Model の利用申請を済ませておきます。



アカウント作成
Hugging Face アカウントを持っていない場合、アカウントを用意します。アカウントは無料で作成できます。
Hugging Face トップページの右上の「Sing up」から作成を開始します。
途中 CAPTCHA 認証を通り、登録するメールアドレスとパスワードを入力します。

登録完了まで画面遷移の指示に従いながら登録を進めます。
Access Token取得
Embedding Model や Open source LLM では取得に Access Token を必要とするモデルが存在します。それらを利用する際には、ハンズオン開始前に発行と値の確保を済ませておきます。
Hugging Face の右上にあるユーザアイコンをクリックすると表示するメニューから「Settings」を選択します。

左ペインの一覧から「Access Token」を選択し、新たに発行する場合には「+ Create new token」ボタンをクリックします。

モデルの利用であれば「Read」権限を選択してから「Token name」に任意の名前を入力し、「Create token」ボタンをクリックして Token を発行します。Token の値は後で確認することはできないので、発行時に必ずメモしておきます。

利用規約に同意が必要な Open source LLM の利用申請
Embedding Model や Open source LLM の中には利用規約に同意を必要とするモデルが存在します。それらを利用する際には、ハンズオンの開始前に利用申請を済ませておきます。
モデルの紹介ページで利用規約への同意が必要な場合はその旨が述べられており、「Expand to review and access」で規約の全文を展開表示をして利用規約を確認します。

規約を最後まで読み進めると、名前、所属と利用目的の入力を求められる場合はそれらを入力してから、「Agree and access repository」ボタンをクリックして同意します。

同意するとモデルの紹介ページに戻りますが、同意の受付状況を確認するために、画面右上のユーザアイコンをクリックすると表示するメニューから「Settings」を選択します。
左ペインの一覧から「Gated Repositories」を選択し、同意したモデルの一覧から「Request Status」の値を確認します。

Request Status が「ACCEPTED」になれば、該当のモデルは利用できます。
環境構築
WSL環境の構築
Windows PC の場合には、 以下手順を参考に WSL と Linux ディストリビューション(Ubuntu)環境を用意します。
Docker環境の構築
コンテナ環境を使うため、以下手順を参考に Ubuntu へ Docker Engine 環境を用意します。
GitHub からハンズオン用のリポジトリ取得
ハンズオンを進めるための環境構築用の設定ファイル、スクリプトや教材を含んだリポジトリを GitHub からダウンロードして取得します。
本章ではコンソールを用いてハンズオンのフォルダ領域を作成して作業を実施します。
$ mkdir -p ~/handson/
$ cd ~/handson/「$ git clone」コマンドで本ハンズオン用のリポジトリを取得します。
$ git clone https://github.com/Toshiharu-Konuma-sti/hands-on-rag-with-langchain.git
$ cd hands-on-rag-with-langchain/コンテナ構築スクリプトの実行
本章ではコンソールを用いて以下のディレクトリで作業を実施します。
$ cd ~/handson/hands-on-rag-with-langchain/container/コンテナ構築用に用意してあるスクリプトを実行して、ハンズオン環境の各種コンテナを構築します。
$ ./CREATE_CONTAINER.shコンテナが構築されてから info オプションを付けてスクリプトを実行すると、ハンズオンに必要なアプリケーションの URL などを表示することができます。
$ ./CREATE_CONTAINER.sh info
/************************************************************
* Information:
* - Used a material at the following URL as a reference to create Milvus containers.
* - https://milvus.io/docs/ja/install_standalone-docker-compose.md
* - Access to Attu (Web admin tool for Milvus) with the URL below.
* - http://localhost:8000
***********************************************************/Attu コンテナが稼働するのでブラウザでアクセスします。

なお、コンテナ構築スクリプトで実行する内容は以下を参照してください。
ツール整備スクリプトの実行
本章ではコンソールを用いて以下のディレクトリで作業を実施します。
$ cd ~/handson/hands-on-rag-with-langchain/setup/ハンズオンで使うツールを整備するために用意してあるスクリプトを実行します。
$ ./SETUP_HANDS-ON.shなお、ツール整備スクリプトで実行する内容は以下を参照してください。
ハンズオン実施
ハンズオンは Python 言語環境で JupyterLab を使って進めます。まずは JupyterLab の実行環境を準備するため、コンソールを用いて以下のディレクトリで作業を実施します。
$ cd ~/handson/hands-on-rag-with-langchain/try-my-hand/JupyterLab で教材の実施
Python 仮想環境のアクティベート
「.venv」名でPython 仮想環境を作成します。
$ python3 -m venv .venvPython 仮想環境の領域にあたる「.venv/」ディレクトリができたことを確認します。
$ ls -laF
:
drwxr-xr-x 7 hoge hoge 4096 Jan 14 12:15 .venv/
:source コマンドで Python 仮想環境に入ります(仮想環境をアクティブにします)。この後は、次章「JupyterLab の起動」に進みハンズオンを開始します。
$ source .venv/bin/activate
(.venv) $- 仮想環境がアクティブになるとプロンプトの先頭に括弧で環境名が表示されます(例:
(.venv))
ハンズオンが終わった際は、ブラウザで JupyterLab を閉じて「deactivate」コマンドを実行して Python 仮想環境から抜けます。
(.venv) $ deactivate
$なお、Python 仮想環境の作成は該当フォルダにある「cmd01-before_python_virtual_env.sh 」でも実行できるようにしてあります。
$ ./cmd01-before_python_virtual_env.sh
:
* Next, enter the command below to go to the python virtual environment!!
source .venv/bin/activate$ source .venv/bin/activate
(.venv) $JupyterLab の起動
Python 仮想環境がアクティブな状態で JupyterLab をインストールします。
(.venv) $ pip install jupyterlabJupyterLab を起動するコマンドを実行します。
(.venv) $ jupyter labコマンドを実行するとコンソールに起動ログが流れ始めます。JupyterLab の起動準備が整うと流れていたログが止まり、起動するための URL が出力されます。
:
[I 2025-01-14 12:34:04.899 ServerApp] Jupyter Server 2.15.0 is running at:
[I 2025-01-14 12:34:04.899 ServerApp] http://localhost:8888/lab?token=d7488a5d324a41c9685cc2e298c5f16d7def9ddf02e50a3b
[I 2025-01-14 12:34:04.899 ServerApp] http://127.0.0.1:8888/lab?token=d7488a5d324a41c9685cc2e298c5f16d7def9ddf02e50a3b
[I 2025-01-14 12:34:04.899 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 2025-01-14 12:34:05.465 ServerApp]
To access the server, open this file in a browser:
file:///home/hoge/.local/share/jupyter/runtime/jpserver-60018-open.html
Or copy and paste one of these URLs:
http://localhost:8888/lab?token=d7488a5d324a41c9685cc2e298c5f16d7def9ddf02e50a3b
http://127.0.0.1:8888/lab?token=d7488a5d324a41c9685cc2e298c5f16d7def9ddf02e50a3b- 上記ログ例では
「http://localhost:8888/lab?token=d7488a5d324a41c9685cc2e298c5f16d7def9ddf02e50a3b」
が起動する URL に該当します。ただし、コマンド実行ごとに token が異なるので、必ずコンソールに出力される URL を起動に利用します。
起動ログに出力された URL にアクセスしてブラウザで JupyterLab を起動します。

なお、JupyterLab のインストールから起動は該当フォルダにある「cmd02-start_jupyterlab.sh 」でも実行できるようにしてあります。
(.venv) $ ./cmd02-start_jupyterlab.sh
:
[I 2025-01-12 00:59:20.643 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
To access the server, open this file in a browser:
file:///home/hoge/.local/share/jupyter/runtime/jpserver-72570-open.html
Or copy and paste one of these URLs:
http://localhost:8888/lab?token=612c96228db1af7175d0c00764360c8a0bbe8ee8322c2291
http://127.0.0.1:8888/lab?token=612c96228db1af7175d0c00764360c8a0bbe8ee8322c2291
:JupyterLab で教材利用
これから示す JupyterLab の使い方を参考に、ステップ1から順番に用意している教材を進めます。
左ペインにあるフォルダアイコンの「File Browser」をクリックしてファイル一覧を表示し、ルート階層から「lesson/」フォルダ配下にアクセスします。

「lesson/」フォルダ配下に rag-step01 ~ rag-step05 のファイル名で始まるステップごとの教材ファイルがあるので、ハンズオンを進めるステップのファイルをダブルクリックして教材をアクティブにします。(最初の教材である「ステップ1」をアクティブにした例)

教材を表示したら左ペインにある目次アイコンの「Table of Contents」をクリックして、ステップの章構成を表示しながら教材を上から順に読み進めます。

教材を読み進めていく過程でソースコードのセルに到達したら、教材上部にある再生アイコンの「Run this cell and advance」(もしくは、セル内で[Ctrl] + [Enter])をクリックして、セル内のソースコードを実行してハンズオンを進めます。

各教材を上から順番に進めていき最終章まで到達したら、そのステップの体験学習は終了です。次のステップに進みながら、ステップ1から5までの各教材を進めることで、RAG の仕組みを実際に体験していきます。
ステップ5の最後のセルは、Web UI の画面を実装するソースコードです。 このセルを実行すると、直下のログ表示部分に RAG の Web アプリケーションを起動する URL が表示されるので、クリックしてアプリケーションを起動します。

Web アプリケーションが起動したら、ステップ1から学習してきた内容の集大成として、RAG の動作を体験してみましょう。

ステップごとの教材内容
ステップごとに用意してある教材でハンズオンできる内容を説明します。
ステップ1

教材の Notebook は以下 GitHub にて確認できます。
該当のステップでは、
RAG に必要な類似検索で利用するベクトルデータベースの環境を整えることを目的に、構造化データとして用意した Excel ファイルをベクトル化してベクトルデータベースに保存する過程を経験します。
ステップ2

教材の Notebook は以下 GitHub にて確認できます。
該当のステップでは、
ひとつ前のステップで構造化データを登録したベクトルデータベースから、サンプルのクエリを投入して類似検索を実行する過程を経験します。
ステップ3

教材の Notebook は以下 GitHub にて確認できます。
該当のステップでは、
質問者から投げかけられたクエリーと類似検索で得られた類似情報を使って、LLM に回答案の作成を依頼するために必要なテンプレートを準備する過程を経験します。
ステップ4

教材の Notebook は以下 GitHub にて確認できます。
該当のステップでは、
ここまでに経験してきた類似検索と準備したテンプレートを活用して、Retriever と Generator を実装する過程を経験します。
ステップ5

教材の Notebook は以下 GitHub にて確認できます。
該当のステップでは、
ステップ2以降で経験してきたナレッジを活用して、Web UI の簡易的な RAG アプリケーションの構築を経験します。
Appendix
ハンズオン環境の構築や設定手順で利用した各種スクリプトや設定ファイルの実装内容について解説します。
コンテナ構築スクリプトの解説
スクリプト「CREATE_CONTAINER.sh 」で実行する内容を説明します。
Milvus 構築用の YAML ファイル取得と加工
ベクトルデータベースを構成する Milvus のコンテナは、以下公式情報からアレンジした手順で構築します。
Milvus の構築は、「Milvus の GitHub リポジトリ」で公開している「docker-compose.yml」(コンテナ定義)を取得して利用します。
$ wget \
https://github.com/milvus-io/milvus/releases/download/v2.5.2/milvus-standalone-docker-compose.yml \
-O docker-compose-milvus.ymlMilvus 提供のコンテナ定義は、ボリュームがバインドマウント方式で管理に root 権限を必要とするため、編集して名前付きボリューム方式に変更します。
services:
etcd:
:
volumes:
- - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
+ - milvus-etcd:/etcd
:
minio:
:
volumes:
- - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
+ - milvus-minio:/minio_data
:
standalone:
:
volumes:
- - ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
+ - milvus-data:/var/lib/milvus
:
+ volumes:
+ milvus-etcd:
+ milvus-minio:
+ milvus-data:Web UI 管理ツール構築用の YAML ファイル用意
Milvus 提供のコンテナ定義は、 Web UI の管理ツールは含まれないので、管理ツールの Attu はコンテナ定義をオリジナルに作りました。
コンテナの構築
用意した「docker-compose-milvus.yml、docker-compose-attu.yml」で一気に構築します。
$ docker-compose \
-f docker-compose-milvus.yml \
-f docker-compose-attu.yml \
up -d全てのコンテナが稼働(STATUS = Up)しています。
$ docker ps -a
CONTAINER ID IMAGE ... STATUS ... NAMES
4b7aadb871bb zilliz/attu:v2.4.12 ... Up 3 minutes ... milvus-attu
62a25fc50463 milvusdb/milvus:v2.5.2 ... Up 3 minutes (healthy) ... milvus-standalone
612a4a6c4a66 minio/minio:RELEASE.2023-03-20T20-16-18Z ... Up 3 minutes (healthy) ... milvus-minio
bf1624b0e410 quay.io/coreos/etcd:v3.5.16 ... Up 3 minutes (healthy) ... milvus-etcdツール整備スクリプトの解説
スクリプト「SETUP_HANDS-ON.sh 」で実行する内容を説明します。
Python 環境の整備
Python 言語環境でハンズオンを進めるため、Python 仮想環境が使えるように Python 環境を整えます。
仮想環境を扱えるように venv モジュールをインストールします。
$ sudo apt install -y python3-venv新たに使いたい Open source LLM の追加実装手順
AI スタートアップ各社が日々しのぎを削り LLM 製品開発が進んでいる状況下で、2024年の年末には新たな LLM として「DeepSeek」が話題になるなど、本ハンズオンの教材を使って新たな Open source LLM を試しに使ってみたくなることがあると思います。そのような場合に、教材に実装されいない Open source LLM を追加で組み込む実装手順を説明します。
事前準備
何はともあれ、新たに試すため追加で組み込みたい Open source LLM の「ダウンロード先(入手先)」と「プロンプトの書式」が必要となります。今回の題材は「DeepSeek」を追加した場合の手順を説明しますが、PCで動かすには大きなパラメータ数の Open source LLM を動かすことはできないので、PC でも動作しそうなパラメータ数が小さく作られた蒸留モデルを探して情報を揃えます。
これにはインターネットをくまなく検索してコツコツと情報を収集して、追加実装するための情報を整理して用意します。
ダウンロード先(入手先)は以下 URL です。
プロンプトの書式は、まだ最良の書式か自信が無い状況ですが、現時点でかき集めた情報として以下の書式で進めます。
<|begin▁of▁sentence|>
あなたは親切で、礼儀正しく、誠実で優秀な日本人のアシスタントです。
context以下に箇条書きでお伝えする情報を使用してuserからの質問に回答してください。
context:
{context}
<|User|>{question}
<|Assistant|>Step 3 でテンプレートクラスを追加
Open source LLM に回答の生成を依頼するにはテンプレートが必要となるため、追加する Open source LLM 用のテンプレートクラスを追加実装します。
教材 Step 3 にて「1. テンプレート生成」の「 【定義】LLM別のテンプレ実装」配下でテンプレートクラスを管理しています。一番最後に存在するテンプレートクラスのソースコードセルをアクティブにすると、セル内側の右上に「Inser a cell below」アイコンが表示するのでクリックして、タイトル用のセルとソースコード用のセルの合計2つのセルを追加します。

追加した2つのセルのうち上側のセルのセルタイプを「Markdown」にして Open source LLM 名を入力します。

下側のセルに他のテンプレートクラスを参考に、追加する Open source LLM 用のテンプレートクラスのソースコードを新たに実装します。

- テンプレートクラスには以下4つのメソッドを実装します
- def get_template_for_use_retriever(self):
類似検索を使う(Open source LLM へ送るプロンプトへ類似検索で取得した関連情報を載せる)場合のテンプレートを実装します。 - def get_template_for_not_retriever(self):
類似検索を使わない(Open source LLM へ送るプロンプトへ類似検索で取得した関連情報を載せない)場合のテンプレートを実装します。 - def extract_answer_from_response(self, response):(self, response):
Open source LLM から得た回答が生成されたレスポンスから、ユーザへ返却する回答文を抽出する処理を実装します。 - def get_additional_template_for_conversation(self):y
一度 Open source LLM から回答を得た後に、継続で Open source LLM へ会話をする場合に、前回のレスポンスに問い合わせを追加するテンプレートを実装します。
- def get_template_for_use_retriever(self):
Step 3 で Open source LLM リストに追記
Open source LLM 管理一覧に、追加する Open source LLM を Hugging Face で公開されている Open source LLM 名で追記します。
追加する Open source LLM に対して、Hugging Face で公開されている Open source LLM 名を取得します。

教材 Step 3 にて「2. OpenLLM一覧作成」の「 【定義】MyOpenLlmList Class」で利用する Open source LLM の一覧を管理しているため、ソースコード内の配列実装の最後の要素に追記します。

Step 3 でテンプレートクラスの組み込み
テンプレートの実装確認を実施するにあたり、先の手順で作成したテンプレートクラスのインポートとインスタンスの生成を実装します。
教材 Step 3 にて「3. テンプレート実装確認」の「対象のLLMとテンプレ選定」でテンプレートクラスのロードとインタンス生成を管理しているため、追加する Open source LLM についてソースコードに実装します。
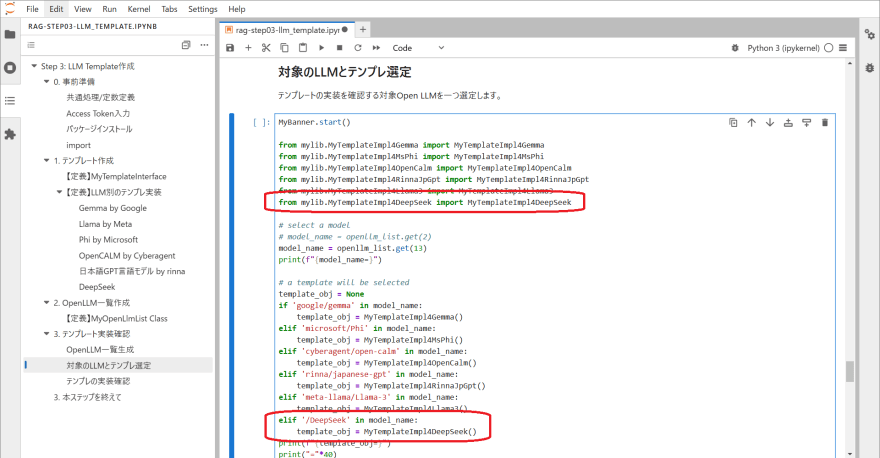
追加する Open source LLM を試すにはモデル名の取得実装箇所で、追加した Open source LLM が定義されている配列要素数を指し示すように変更します。

Step 3 の実装がここまでできたら、あとは Step 3 を先頭から全セルを実行してテンプレートの出来具合を確認します。回答結果が今一つと思う場合には、テンプレートクラスに書いたテンプレートを見直して再度実行を繰り返しテンプレートの品質を上げていきます。
Step 4 でテンプレートクラスの組み込み
Step 4、および Step 5 にて追加する Open source LLM を活用するにあたり、先の手順で作成したテンプレートクラスのインポートとインスタンスの生成を実装します。
教材 Step 4 にて「2. 生成: ②.Generator」の「 【定義】Generator Class」でテンプレートクラスのロードとインタンス生成を管理しているため、追加する Open source LLM についてソースコードに実装します。


Step 4 の実装がここまでできたら、あとは Step 4 を先頭から全セルを実行して Generator クラスの実装具合を確認します。
Step 5 の Web UI で追加した Open source LLM を使えるようにする
Step 5 の Web UI で追加する Open source LLM を利用するにあたり、該当の Open source LLM をメモリへロードする対象として指示します。
教材 Step 5 にて「2. 生成: Generator」の「 【生成】OpenLLM一覧」でインスタンス生成する際の引数で Web UI で使う Open source LLM を管理しているため、追加した Open source LLM の配列要素を指定するように改修します。
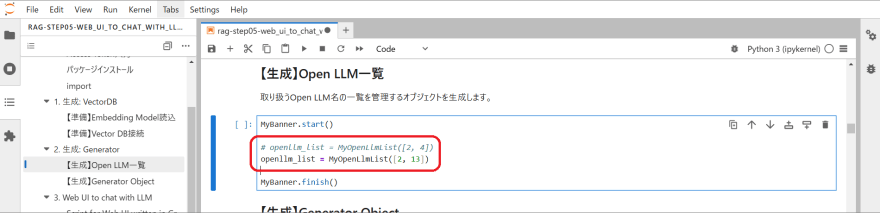
Step 5 の実装がここまでできたら、あとは Step 5 を先頭から全セルを実行して Web UI の実装具合を確認します。
PC 性能別のモデル処理時間比較
ローカルでモデルを利用した処理は、PC 環境の性能差により処理時間に差が生じるので計測して比較してみました。
- 計測処理:教材「Step03: LLM Template 作成 > 3. テンプレート実装確認 > テンプレの実装確認」章のセルに実装されているソースコードを利用します。
- 処理内容:検証用に用意した固定の質問と類似検索結果を基に Open source LLM に回答生成を依頼します。
- 利用した Open source LLM: google/gemma-2-2b-jpn-it · Hugging Face を利用します。

まとめ
オープンソースと JupyterLab に用意した教材を使った、RAG の体験はいかがでしたでしょうか?ローカル LLM を使うので、ある程度の PC スペックが必要となってしまうのはご容赦頂くとして、RAG の仕組みの理解と、LLM を使ったプログラム制作のモチベーションを高める切っ掛けになってもらえたら嬉しいです。


