

はじめに
こんにちはサイオステクノロジーの小野です。前回はOpenShift AIのモデルサービング機能を用いて、推論APIを実装しました。今回はOpenShift AIのもう一つの重要な機能であるデータサイエンスパイプラインを実装します。パイプラインを利用することでモデル開発を高速化することが可能になります。MLOpsの実現には欠かせない機能なので、しっかり実装できるようにしましょう。
データサイエンスパイプラインについて
データサイエンスパイプラインとは、機械学習のワークフローを標準化および自動化し、データサイエンスモデルを開発およびデプロイします。
OpenShift AI(バージョン2.9以降)ではKubeflow Pipelines バージョン2.0を利用してパイプラインを実行しています。
Kubeflow Pipelines バージョン2.0はワークフローエンジンとしてArgo Workflowを利用しています。
パイプラインの種類
パイプラインの実装方法は2通りあります。
Elyra
ElyraはJupyterLab上でGUIを利用してパイプラインを構築できます。パイプラインで自動化したいソースコードファイルをドラッグ&ドロップし、そのファイル同士に線を引くだけで構築できるので、直感的にパイプラインを構築できます。
パイプラインの実行もJupyterLab上で簡単に実行できるので非常にお手軽です。
また、Kubeflow Pipelines形式にエクスポートすることも可能です。
Kubeflow Pipelines SDK
Kubeflow Pipelines SDKはPythonコードを使用して作成したパイプラインをyaml形式にコンパイルするSDKです。
Pythonでパイプラインを構築するので、細かい処理や設定を行うことが可能です。
パイプラインの実装例
今回はパイプラインの設定を行い、データの準備からモデルの更新を行うところまで行うパイプラインを構築します。
MLOpsに対応する部分としては以下のようになります:

今回実装するパイプラインに対応するMLOpsの範囲
今回実装するパイプラインでは、データの準備、モデルの学習、モデルの提供を作成しております。
パイプライン概要

今回実行するパイプラインの構成
- 1_dataprocessed.ipynb(データの準備)
- 画像データをS3からダウンロードして、学習がしやすい形に前処理を行います。その後、前処理済み学習データをS3にアップロードします。
- 2_training.ipynb(モデルの学習)
- 前処理を行った学習データをS3からダウンロードして、モデルの学習を行います。その後、ONNX形式にモデルをエクスポートし、S3にアップロードします。
- 3_modeldeploy.ipynb(モデルの提供)
- モデルサーバーを更新して、モデルの再デプロイを行います。
パイプライン構成図
パイプラインの構成図は以下に示します。
- ➀ユーザーのパイプライン実行
- ②パイプラインアーティファクトと呼ばれるパイプライン情報をS3に保存
- ③パイプラインサーバーのパイプライン実行におけるパイプライン情報取得
- ④パイプラインのコードを順次実行
- ⑤1_dataprocessed.ipynbにおける画像データの取得
- ⑥1_dataprocessed.ipynbによって前処理した学習データのアップロード
- ⑦2_training.ipynbにおける学習データの取得
- ⑧2_training.ipynbによってONNX形式にエクスポートした学習モデルのアップロード
- ⑨3_modeldeploy.ipynbによるモデルサービングサーバーの更新
- ⑩モデルサービングサーバー再起動によるモデル再デプロイ

パイプラインの構成図
前提条件
- OpenShift AI:2.13
- データサイエンスプロジェクト作成済み
- 以前の記事を参考にしてください(OpenShift AI を導入してみた)
- データ接続設定済み
- 以前の記事を参考にしてください(OpenShift AIで機械学習をやってみた)
- モデルデプロイ済み
- 以前の記事を参考にしてください(OpenShift AIのモデルサービング機能について)
- 注意:ワークベンチをすでに作成している場合はパイプラインサーバーを設定した後に作り直してください。
パイプラインサーバー設定
OpenShift AIのデータサイエンスプロジェクト内のPipelineというタブを開いて下さい。Configure pipelineを押下すると設定画面が開きます。S3ストレージの接続設定が行えるので、データ接続と同じ設定にするか新しくS3の接続情報を入力してください。

パイプラインサーバー設定
この接続先にパイプラインのアーティファクトと呼ばれるパイプラインの実行に必要な情報や実行した際の中間成果物が保存されます。
ワークベンチ作成
パイプラインサーバーを作成した後にワークベンチを作成します。作成方法は以前の記事を参考にして下さい。(OpenShift AIで機械学習をやってみた)
サービスアカウント設定
今回構築するパイプラインにはモデルの更新を行う処理が含まれています。したがって、パイプラインを動作させるサービスアカウントに対して、モデルサーバーの設定を行うinferenceserviceというリソースとモデルサーバーのポッドを管理するDeploymentを操作する権限を付与する必要があります。
最初にOpenShiftコンソールからユーザー管理 > Rolesを開きます。Roleの作成を押下し、InferenceserviceとDeploymentを操作する権限があるロールをyamlで作成します:
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: pipeline-modeldeploy-role
namespace: test-ai # ロールが属するネームスペースを指定
rules:
- verbs:
- get
- list
- watch
- create
- update
- patch
- delete
apiGroups:
- serving.kserve.io
resources:
- inferenceservices
- verbs:
- get
- list
- watch
- create
- update
- patch
- delete
apiGroups:
- apps
resources:
- deployments

ロール設定
次に作成したロールとパイプラインを動作させるサービスアカウントにロールバインディングを設定して連携させます。
ユーザー管理 > RoleBindingsを開いてください。
バインディングの作成を押下して、以下のように設定してください:
- バインディングタイプ:namespace のロールバインディング (RoleBinding)
- 名前:ロールバインディングの名前
- Namespace:ロールバインディングが属するネームスペース
- Role名:先ほど作成したロールの名前
- サブジェクト:ServiceAccount
- namespaceの選択:データサイエンスプロジェクト名(サービスアカウントが属するネームスペース)
- サブジェクトの名前:pipeline-runner-dspa

ロールバインディング設定
これでパイプラインでモデルの更新ができるようになりました。
パイプラインの実装
それではいよいよパイプラインを実行します。今回はElyraを用いてパイプラインを構築します。以下のリンクからファイルをダウンロードし、JupyterLabにアップロードしてください。
パイプラインの実行前に0_dataupload.ipynbを実行して、S3内に画像データを保存してください。すでに実行している場合は省略して下さい。
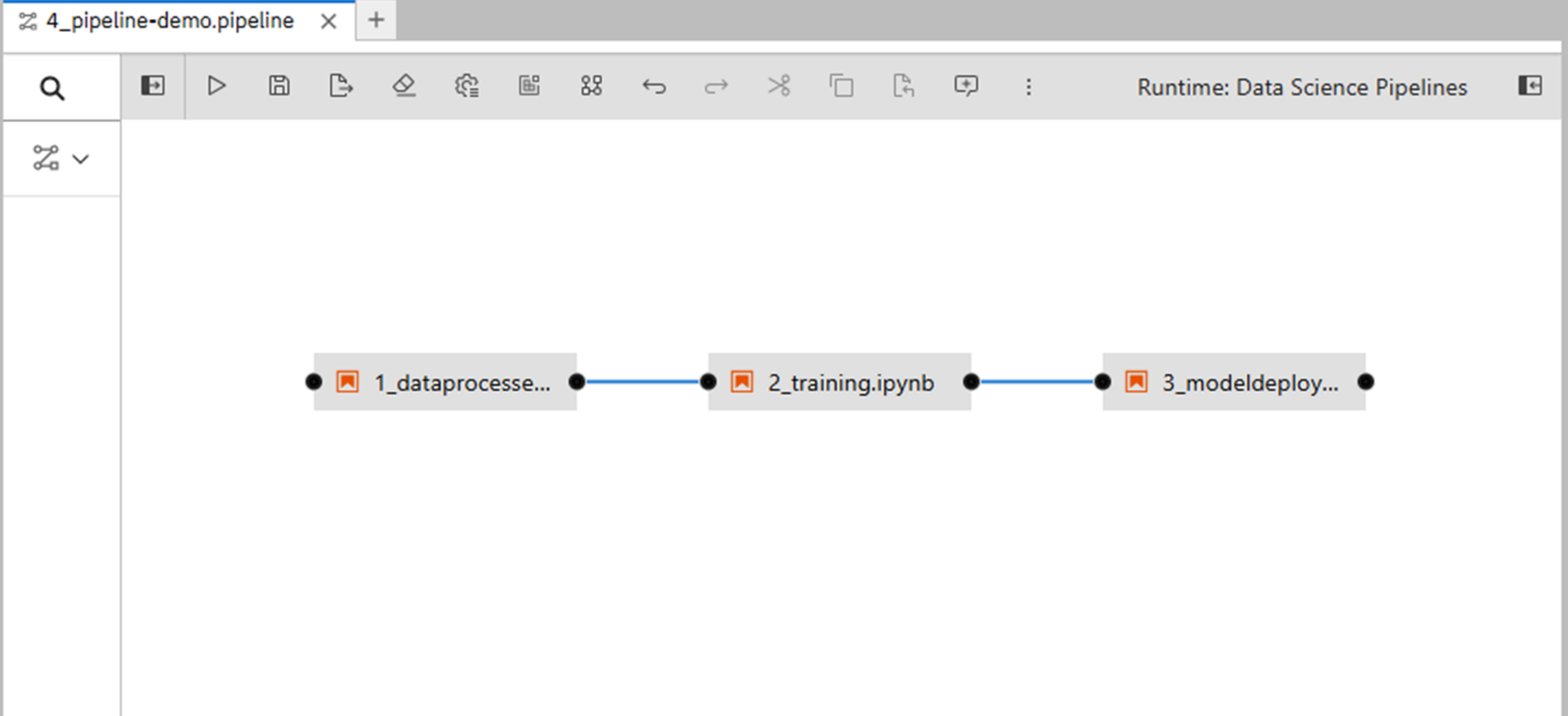
4_pipeline-demo.pipelineファイルを開いてください。1~3のプログラムがつながったパイプラインが確認できます。

Elyraの画面
Elyraの上部メニューのRun pipelineを押下するとパイプラインを実行できます。

Run pipelineによりパイプラインの実行が可能
OpenShiftAIのコンソール画面に移動して、データサイエンスプロジェクトのPipelineのタブを開いてください。
実行したパイプラインと同じファイル名(4_pipeline-demo)のパイプラインが実行されているのが確認できます。
また、パイプライン名の左の▶を押下するとパイプラインのバージョンを確認できます。

パイプライン一覧
その一番新しいバージョンのメニューをクリックして、View runを押下すると実行中のパイプラインを確認することができます。

メニューからView runより実行中のパイプラインを表示できる
実行されているパイプラインを開くとパイプラインの進行状況を確認できます。

実行中のパイプライン
パイプラインの実行がSuccseedになったら実行完了です。

Succseedになったら実行完了
もしエラーが起きてFailedとなったら該当のプログラムをクリックして、ログを確認してみてください。

パイプラインのログ確認
次にパイプラインのアーティファクトが保存されているのを確認します。S3に移動して実行したパイプラインのバージョンと同じ名前のディレクトリが作成されていることが分かります。

パイプラインのアーティファクト保存場所
そのディレクトリの中身を見ると、パイプラインで実行した1~3のプログラムが圧縮されて保存されていたり、htmlにエクスポートされ保存されたりしています。

パイプラインのディレクトリ中身
最後に
今回はデータの取得からモデルの更新を行うパイプラインを実行しました。パイプライン機能をうまく活用して、AIを効率よく開発してみてください。次回はパイプラインのスケジュール設定を解説します。
参考
- Kubeflow Pipelines:https://www.kubeflow.org/docs/components/pipelines/
- パイプライン設定:https://docs.redhat.com/ja/documentation/red_hat_openshift_ai_self-managed/2.13/html/working_with_data_science_pipelines/index
- 前回:OpenShift AIのモデルサービング機能について



{kind=link}